Kafka 리벨런싱으로 인한 이슈 처리
현상
APM 경고와 함께 로그양이 증가되는 현상이 발생했습니다.
이를 감지하고 컨테이너에 접속해서 로그를 확인한 결과(로그가 지속적으로 발생하여 APM web이 응답없음이 지속적으로 발생하여 어쩔수 없이 컨테이너에 직접 접속) Kafka CommitException이 발생하고 있었습니다.
아래는 실제 발생한 로그입니다.
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records. at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.sendOffsetCommitRequest(ConsumerCoordinator.java:820) ~[kafka-clients
원인
원인은 카프카 Consumer poll, record 등 설정으로 인한 이슈였습니다. kafka poll 의 동작을 알면 더 이해하기 쉽습니다.
카프카 consumer는 어떻게 동작하나?
카프카는 기본적으로 topic당 하나의 consumer group을 배치합니다.
topic의 partition 수만큼 consumer 의 수에 맞게 설정을 합니다. 적거나 많으면 효율적으로 컨슈머가 일을 하지 않기 때문이죠.
아래 그림처럼 consumer 가 partition보다 많으면 컨슈머는 일을 하지 않고 놀게됩니다.
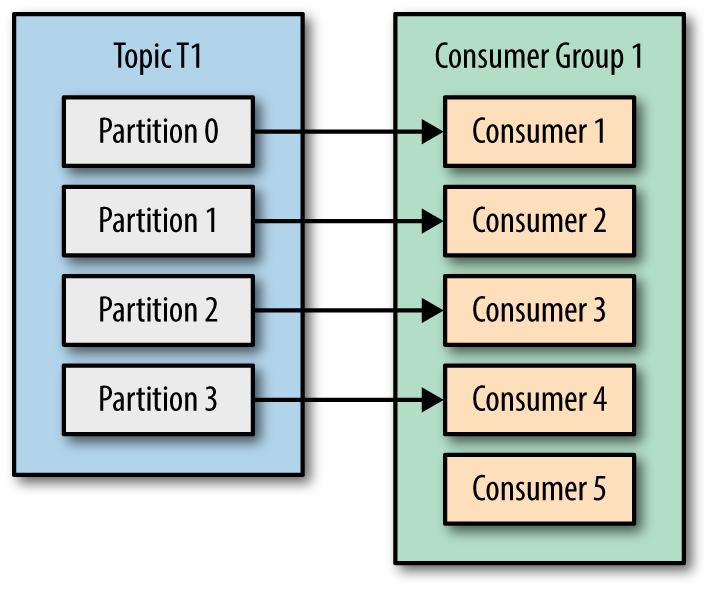
또 아래그림처럼 파티션보다 부족하면 컨슈머들이 바쁘게 일하며 효율적으로 일처리를 하지 못하겠죠.
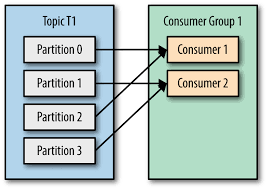
그래서 아래처럼 배치하면 노는 consumer 없이 열심히 일을 하게 됩니다.
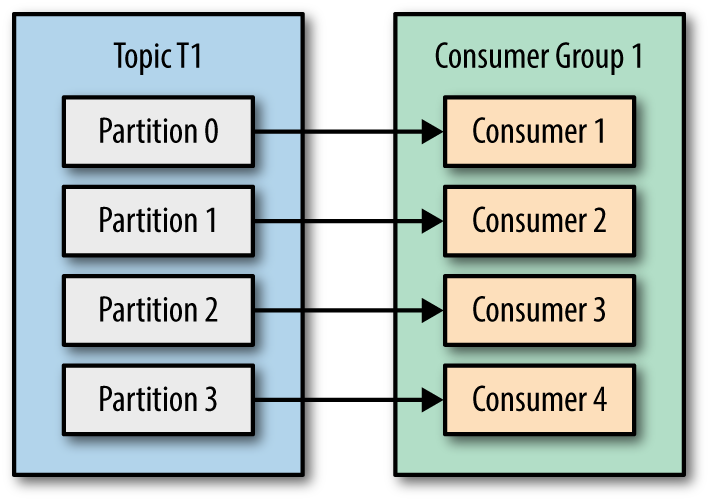
consumer 는 위와 같이 배치되고 poll 시그널을 보내 topic에서 데이터(record)들을 가져오는데요. consumer 설정하여 데이터, 시간을 지정할 수 있습니다.
제가 설정한 kafka 아래와 같은 설정을 하고 있었습니다.
max.poll.records=500
max.poll.interval.ms=5m
heartbeat.interval.ms=3sec
session.timeout.ms=10sec
각 옵션에 대한 설명
max.poll.records # poll을 할때 처리할 record수
max.poll.interval.ms # poll 부터 commit까지 기다리는 시간.
heartbeat.interval.ms # consumer group coordinator(리더 컨슈머)와 group간 세션(session.timeout)이 살아있는지 확인함.
session.timeout.ms # heartbeat 시그널을 받지 않고 유지되는 시간.
각 옵션의 시간이 지나면 컨슈머는 종료, 장애라 판단하고 리벨런싱을 수행합니다.
리벨런싱은 장애,오류가 발생한 컨슈머를 다른 컨슈머로 보내거나 제거하는 과정.
이슈 발생 원인
이슈가 발생한 상황을 설명하겠습니다.
우선 발생한 topic은 user-created 이벤트 이며, 사용자를 저장하고 이벤트를 보내 사용자를 확인하고 특정 로직을 수행하는데 사용자를 확인하는 과정에서 가입자와 트래픽이 몰렸고, user-created 이벤트보다 사용자 확인 과정이 느려 가입전 notFoundException이 발생했습니다. 예외에 대해서 retry 하는 과정(사용자 조회과정)에서 조회 속도가 늦어지고, 반복적으로 리벨런싱을 수행했고 완료되지 않은 작업을 (저장되지 않은 사용자에 대해서 조회) 다시 수행하다보니 NotfoundException으로 계속 retry를 하여 infinite rebalancing이 발생했습니다.
현재의 설정 session.timeout, heartbeat, max.poll.interval.ms 설정안에 처리를 할 수 없었고, 계속적인 리밸린싱 문제로 로그가 계속 쌓이고 consumer lag또한 발생했었습니다.
해결
이 과정을 처리하기 위해서는 카프카 consumer를 모니터링하고 설정을 해주는건데요. 우선적으로 poll.interval.ms 와 session.timeout, max.poll.records의 설정을 수정했습니다.
max.poll.records=100
max.poll.interval.ms=10m
heartbeat.interval.ms=10sec
session.timeout.ms=10m
위처럼 수정 후 kafka 모니터링을 한 결과 모두 정상적으로 작동했으며, consumer-lag 또한 없어졌습니다.