Redis 정리 (1)
NoSQL
- Not Only SQL의 약어이며, RDB가 처리하는데의 비용과 성능 개선을 위한 목적으로 개발되었다.
- NoSQL은 세가지의 종류가 있음.
- KeyValue : Redis, Memcached
- Column-Family : Hbase, Cassandra
- Document Oriend Store: MongoDB, CouchDB .
Read 증가에 따른 R/W분리
- 일반적으로 서비스에 Read가 많을 경우 R/W를 분리하여 부하를 분산시키는 방법을 사용한다.
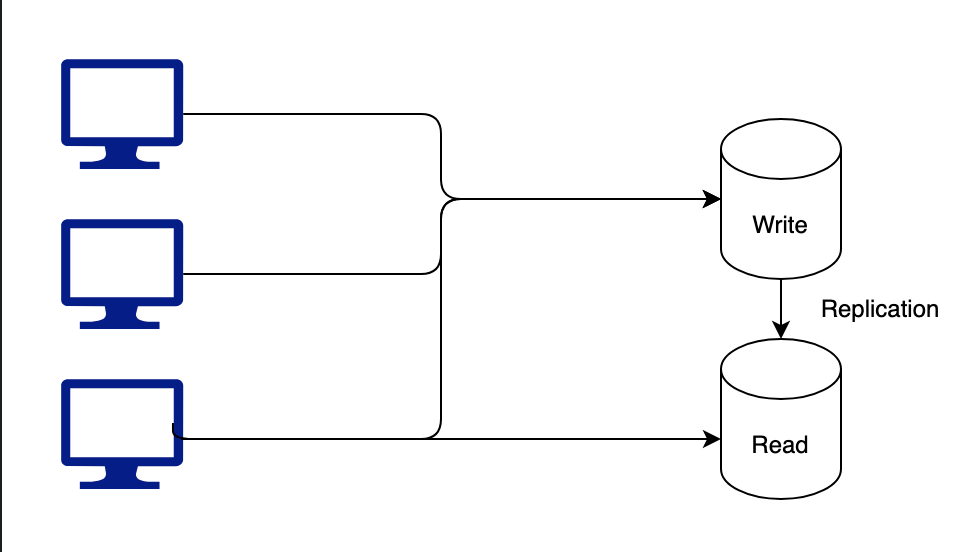
- 위와 같이 분리하면 부하가 분산되며 꽤 안정적으로 운영가능하다.
Read를 분리시켰을 때 일관성에 문제가 생길 수 있는데 데이터의 Sync를 맞추는 과정에서 발생하는 문제점이다. 이것도 시간이 지나면 데이터의 Sync가 맞춰지는데 이를 Eventual Consistency라 한다.
Write가 증가에 따른 파티셔닝
- 결국 I/O의 총 성능은 Write + Read의 성능인데, Write에서 병목이 생긴다면 이를 파티셔닝해서 해소하는 방법이 있다.
- 파티셔닝에는 수직, 수평 파티셔닝이 있다.
- 수직 파티셔닝 (Vertical)은 테이블의 Column별로 분산하여 저장하는 방법입니다. 예를들면 Column A는 A서버 B는 B서버에 저장하는 것입니다.
- 수평 파티셔닝 (Horizontal)은 샤딩이라고도 부르며, 특정 범위는 A서버 그 다음범위는 B서버에 나눠 저장하는 것입니다.
- 샤딩에 방법에는 Range, Hash, Consistent Hashing 방법이 있습니다.
- 파티셔닝을 하면 성능 향상은 되지만 그만큼 관리포인트와 비용이 생기는 단점이 있어 적절한 시기에 파티셔닝하는게 좋다.
Consistency Hashing
- Consistency Hashing 은 David karger라는 사람이 분산리퀘스트를 효율적으로 처리하기위해 고안해낸 방법이다.
- 분산 서버로 구성되어있는 경우 하나에 서버가 장애가 발생했을 때 해당 세션에 연결되어있는 유저의 정보나 다른 서버로 연결을 해줘야하는 등의 문제점이 있다. 이를 Consistency hashing을 사용해 쉽고 효율적으로 분배할 수 있다.
- Consistency Hashing의 핵심은 hash함수이다. hash함수는 hash 함수가 변경되지 않는이상 파라미터에는 항상 같은 결과가 나온다는게 특징이다. 예를들면 A서버가 있는데 hash함수를 사용하면(
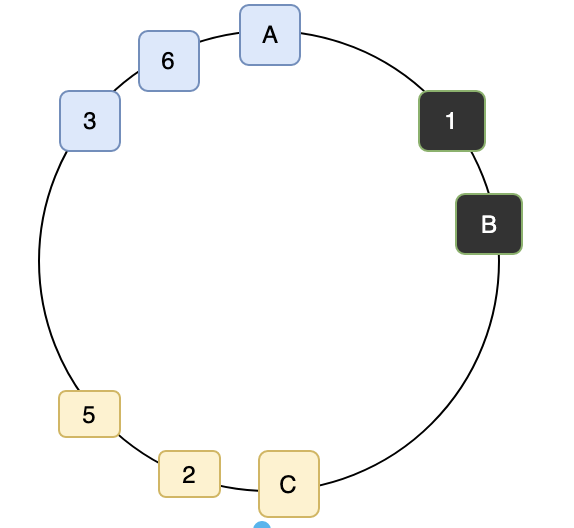
hash(A)) 값이 항상 같다. - Consistency Hashing은 HashRing을 사용하는데 가상으로 Ring형태를 만들고 그 안에 각 서버를 배치한다. 아래 그림을 보면 이해가 쉽다.
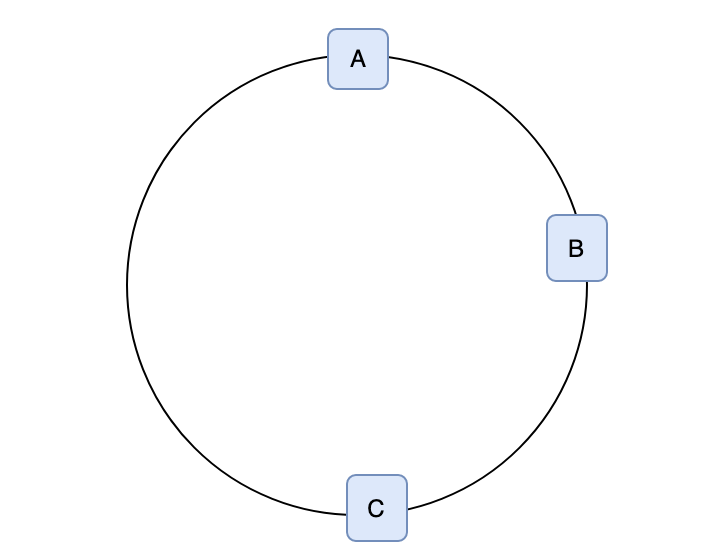
- 위처럼 배치를 하고 hash수행 후 각 서버의 결과가 A(0.5), B(1.5), C(2) 가 나온다 가정하고 요청이 올 경우 특정 key에 대한 hash의 결과가 값이 크거나 같은(가까운) 서버에 저장된다고 가정을 했을 때, hash(‘1’) =
0.5이면0.5 <= 1으로 B서버에 저장이 된다. 또 hash(‘test2’) =2이면2 <= 2로 C에 저장이 된다. 차이가 같을 때는 어디로 가던 상관없다 하지만 규칙은 있어야 한다.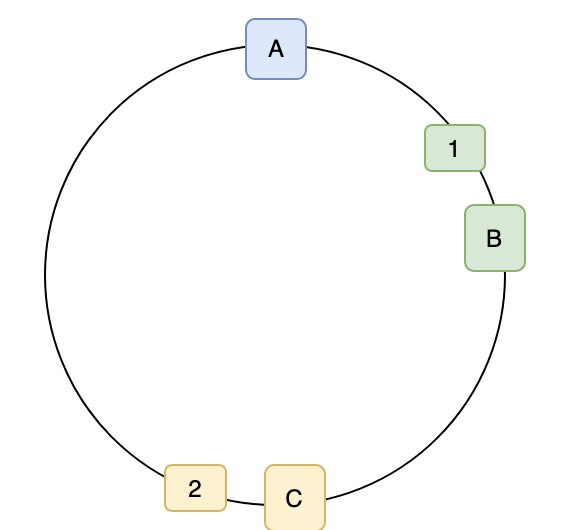
- 배치 후 결과
- 만약 위처럼 장애가 발생했을 경우 다시 적용했던 방식대로 크거나 같은(가까운) 쪽으로 이동하게 된다.
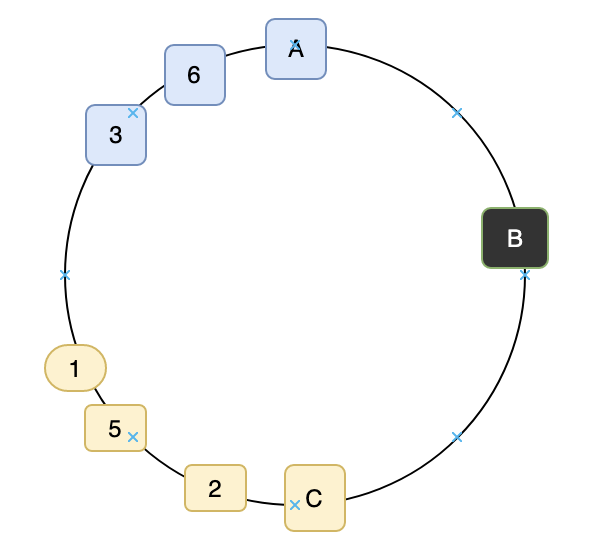
- 위 그림은 장애 발생 후 분배된 결과
- 그런데 이렇게 되면 한 서버에 부하가 높아져서 전체적으로 장애전파가 되지 않을 까라는 생각이들 수 있는데 아래 그림처럼 서버에 값을 +1 +2 +3 식으로 해시값을 더 만든다.